One important part of the implementation of the EXT_external_objects and EXT_external_objects_fd groups of extensions for iris (the Intel gallium OpenGL driver) was the semaphore synchronization (EXT_semaphore extension). We’ve seen how the GL semaphores structs and functions that are introduced by this extension should be used in previous interoperability posts. In this post, I’ll try to describe the methods we’ve used to debug the EXT_semaphore implementation itself as well as the fences backend of the iris driver without getting into many driver internals details.
We are going to see some hacks I’ve used to validate that glWaitSemaphoreEXT was indeed blocking the GL server until rendering is done and glSignalSemaphoreEXT could indeed unblock the server the right moment for the next API to take control over the shared resources.
Some of the debugging ideas I’ll describe came to me from other people’s bug reports and contributions. They are all mentioned in the Acknowledgements section of this post. Half of this work was part of my work for Igalia ‘s graphics team and half was done as a hobby after I was moved to Igalia’s WebKit team.
glWaitSemaphoreEXT
When glWaitSemaphoreEXT is called the GL server is supposed to block and wait until it’s signaled. And so, we needed to verify that this was indeed happening in our test programs for Piglit. Let’s see how:
Most image and pixel buffer tests we’ve seen so far in previous posts have a similar flow:
- Shared resources (textures or buffers) are created from Vulkan and are imported into OpenGL using the interoperability extensions.
- Vulkan draws something using those resources while OpenGL is waiting.
- OpenGL draws something using the shared resources after it takes back the control.
- We display a picture that helps us validate that the shared resources were successfully imported into OpenGL and/or modified from OpenGL.
Waiting in those tests takes place while Vulkan is rendering on the shared resource. Shared textures and buffers used in the Vulkan renderpass never exceed the default size of a Piglit window which is quite small (about 160×160), and the process to fill them with pixels is not complex at all: we usually render stripped patterns, a single color (clear), or rectangles. This means that the Vulkan drawing is completed quickly, and so we can’t really tell if the server was blocked during it: with such a low workload, the Vulkan rendering could had been completed before OpenGL had taken control over the resource even without external synchronization. In order to check the waiting, we’d need to render more pixels in a bigger window, and draw a more complex scene that would require many GPU calculations for a long time (and ideally this time should be configurable). Then we could let Vulkan draw for a very long time on a shared texture, display it with OpenGL and check if all pixels have been rendered during the time OpenGL was waiting for Vulkan to finish.
To validate this, I’ve written such a test, but I couldn’t add it to Piglit as it wouldn’t be a good idea to add a test that consumes all the GPU power and takes ages to run inside a testing framework! And so, I am going to describe it here.
Let’s see the idea in detail:
I wanted the test to render something complex, and so, I’ve modified one of my hobby pixel shaders the one appearing in this post to work with Vulkan:
This shader draws mushrooms in hills, by ray marching distance fields [3]. Objects and surfaces of that scene are procedurally generated using distance functions with a configurable step. When this step is small, the image is more detailed and “dense” (=> we perform the distance calculations for more pixels), and so the rendering is slower. When it’s big we generate less detailed scenes and the rendering is faster.
Because the number of calculations in the shader could be increased or decreased by modifying the step of the distance functions, the pixel shader was ideal to check the waiting: I could reduce the step until the GPU is hanged from running out of memory (if I lower the step too much all GPU memory will be consumed and so, the system will run out of memory), and then find the lower step that is not hanging the GPU to use it in my experiments. That would really cause the rendering to be as slow as possible :D.
So the program flow would be the one we’ve seen so far in vk-image-display but modified to use the ray marching shader with a configurable step in distance functions:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
enum piglit_result piglit_display(void) { [...] GLuint layout = gl_get_layout_from_vk(color_in_layout); if (vk_sem_has_wait) { glSignalSemaphoreEXT(gl_sem.gl_frame_ready, 0, 0, 1, &gl_tex, &layout); glFlush(); } /* VULKAN CLEARS THE FRAMEBUFFER AND FILLS THE SHARED TEXTURE VERY SLOWLY */ vk_draw(...); layout = gl_get_layout_from_vk(color_end_layout); if (vk_sem_has_signal) { glWaitSemaphoreEXT(gl_sem.vk_frame_done, 0, 0, 1, &gl_tex, &layout); glFlush(); } /* OPENGL DISPLAYS THE SHARED TEXTURE AS SOON AS IT TAKES CONTROL */ [...] } |
You can find the test in this piglit branch. Check it out, build piglit, and run ./build/bin/ext_external_objects-vk-semaphores3 to run the test.
Code: https://gitlab.freedesktop.org/hikiko/piglit/-/commits/wip/gallium-sync-problem
Expected result:
If the GL server was blocked for as long as Vulkan was rendering pixels on the texture, we’d wait for a long time and at the end we’d see a scene with a mushrooms field on screen, displayed by OpenGL after signaling. If the server wasn’t blocked until the rendering was completed, then at the time OpenGL would access the shared image to display it some pixels would still have the color that was used to clear the framebuffer from Vulkan before the rendering (that color is purple).
What really happened:
I’ve ran the program with various steps and the result was purple, purple, purple, and a few mushroooms on my BDW GPU (which is old, trying this in more modern hardware is faster but still returns purple regions for smaller steps).
| STEP = 0.004 |  |
| STEP = 0.002 |  |
| STEP = 0.001 |  |
I’ve then ran the same test on a radeonsi driver (which is also following the Gallium design) and the result was very similar: there were always purple pixels…
At first I thought there must be some problem that affects all gallium drivers. I knew that not many people would intentionally stress the GPU so much but I couldn’t convince myself it was possible to have such a bug on mesa…
So, I’ve discussed the problem with Tapani Pälli and learned from him that this was not a Gallium bug… but a kernel feature… 😀
Linux kernels from 5.5 and on send a periodic heartbeat in time intervals that can be modified from /sys/class/drm/card0/engine/rcs0/preempt_timeout_ms. So, when the GPU is busy for a long time they can detect it and stop it to prevent potential hangs.
I’ve used drm-tip from here and these instructions to build the latest kernel and I’ve set the DRM_I915_HEARTBEAT_INTERVAL parameter to 0. According to the documentation of CONFIG_DRM_I915_HEARTBEAT_INTERVAL, it may be 0 to disable heartbeats and therefore disable automatic GPU hang detection.
After that, I’ve tried sequential runs where I was reducing more and more the STEP value of the distance function in the pixel shader.
Below is a picture of the piglit test running with STEP = 0.0001 (the smallest I’ve achieved without hanging my BDW). Rendering took ages but there were no purple pixels, which means that the GL server was indeed blocked waiting for Vulkan to draw the mushroom scene!
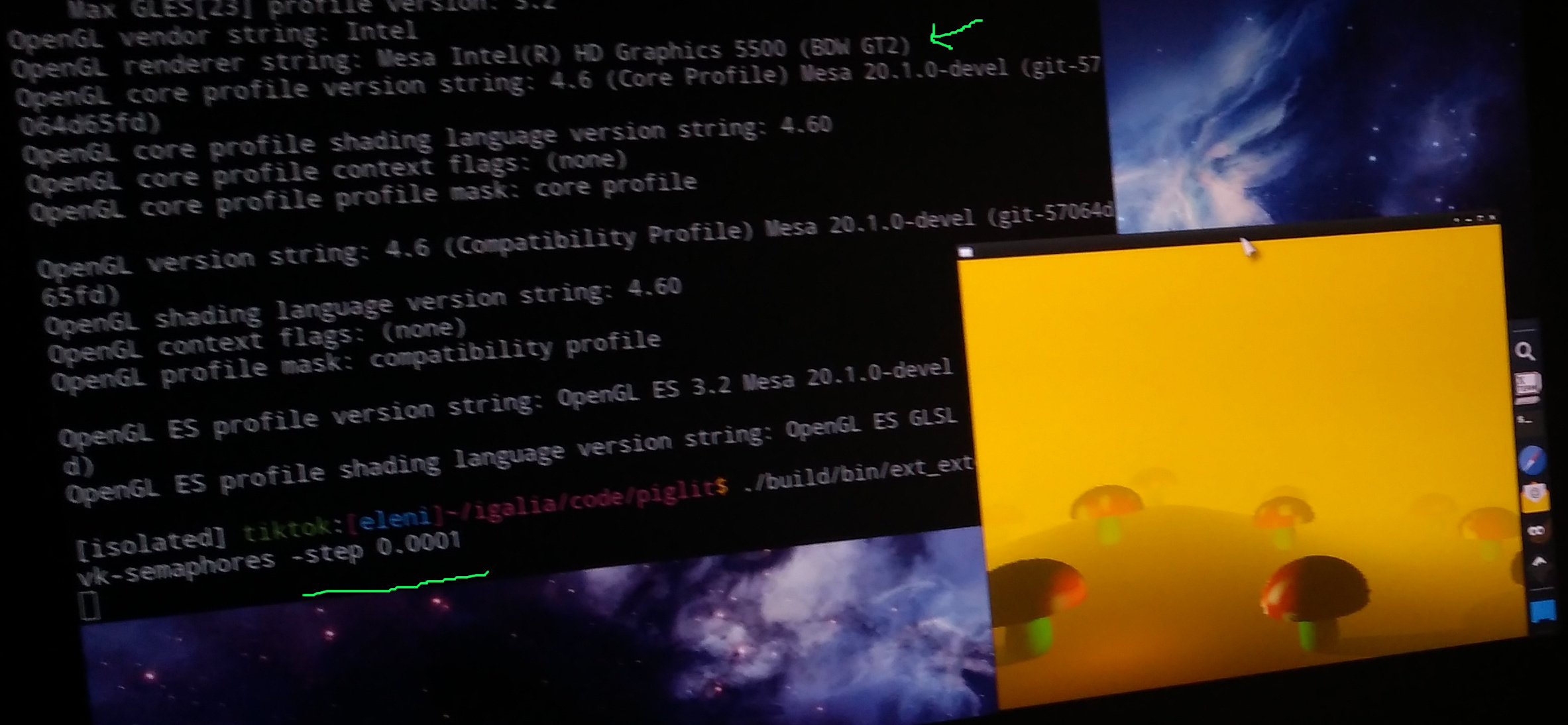
(Rendering this scene with such a low STEP made my laptop so unusable that I couldn’t even take a proper screenshot!)
So, glWaitSemaphoreEXT was working as expected! Now, I had to find a method to test signaling.
Debugging glSignalSemaphoreEXT
Testing signaling was easy, or so I thought in the beginning… 😀 In a simplified version of piglit_display above I had done:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
piglit_display(void) { [...] glSignalSemaphoreEXT(gl_sem.gl_frame_ready, 0, 0, 1, &gl_tex, &layout); glFlush(); /* VULKAN DRAWING */ vk_draw(...); glWaitSemaphoreEXT(gl_sem.vk_frame_done, 0, 0, 1, &gl_tex, &layout); /* OPENGL DISPLAYS THE SHARED TEXTURE AS SOON AS IT TAKES CONTROL (WHEN IT'S SIGNALED) */ gl_draw(...); [...] } |
If signaling was not working, then the Vulkan rendering wouldn’t start and nothing would appear on screen. Because I was able to see a picture, I assumed signaling was working well too.
But only a few weeks after EXT_semaphore, EXT_semaphore_fd had been merged into mesa, a fences backend optimization broke this extension. Mario Kleiner (see acknowledgments) brought this to our attention and made me think of new tests to check potential edge cases of signaling.
Let’s first see the problem that occurred and then what other use cases we had to check in case of glSignalSemaphoreEXT:
EXT_external_objects extension requires we call
glSignalSemaphoreEXT followed by a
glFlush. But if the rendering workload is small when flushing takes place, the OpenGL driver batch buffer might have been submitted already (after signaling) and so, the driver fence that corresponds to the semaphore might not be submitted to the kernel. Then when the Vulkan driver attempts to wait on that shared VkSemaphore/fence there isn’t one and the batch buffer is rejected by the kernel returning an error.
We’ve fixed this issue by slightly modifying Mario’s patch for the bug we had (see acknowledgments) but we realized that our tests didn’t cover this particular edge case. And so, I’ve written some new ones that could catch problems like this.
The idea was to check if a really fast rendering that could be completed before glFlush could cause invalid submissions.
So the two new semaphore tests would check the following cases:
- OpenGL clears the shared texture before Vulkan takes control.
- Vulkan renders something very fast and simple in the shared texture before OpenGL takes control.
Let’s see each case:
In vk-semaphores test (vk_semaphores.c), we perform an initial rendering using Vulkan, and then in display, we clear the framebuffer to red using OpenGL. The expected result is to see a red window. If there’s any problem with the OpenGL rendering and the signaling we are going to see the image that was rendered by Vulkan, and if there’s a problem with the submission we are going to see an error from the driver.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 |
void piglit_init(int argc, char **argv) { /* [...] */ if (!vk_init(w, h, d, num_samples, num_levels, num_layers, color_format, depth_format, color_tiling, depth_tiling, color_in_layout, depth_in_layout, color_end_layout, depth_end_layout)) { fprintf(stderr, "Failed to initialize Vulkan, skipping the test.\n"); piglit_report_result(PIGLIT_SKIP); } /* create memory object and gl texture */ if (!gl_create_mem_obj_from_vk_mem(&vk_core, &vk_color_att.obj.mobj, &gl_mem_obj)) { fprintf(stderr, "Failed to create GL memory object from Vulkan memory.\n"); piglit_report_result(PIGLIT_FAIL); } if (!gl_gen_tex_from_mem_obj(&vk_color_att.props, gl_tex_storage_format, gl_mem_obj, 0, &gl_tex)) { fprintf(stderr, "Failed to create texture from GL memory object.\n"); piglit_report_result(PIGLIT_FAIL); } if (!gl_create_semaphores_from_vk(&vk_core, &vk_sem, &gl_sem)) { fprintf(stderr, "Failed to import semaphores from Vulkan.\n"); piglit_report_result(PIGLIT_FAIL); } if (!gl_init()) { fprintf(stderr, "Failed to initialize structs for GL rendering.\n"); piglit_report_result(PIGLIT_FAIL); } /* one initial vk rendering to fill the texture */ GLuint layout = gl_get_layout_from_vk(color_in_layout); if (vk_sem_has_wait) { glSignalSemaphoreEXT(gl_sem.gl_frame_ready, 0, 0, 1, &gl_tex, &layout); glFlush(); } struct vk_image_att images[] = { vk_color_att, vk_depth_att }; vk_draw(&vk_core, 0, &vk_rnd, vk_fb_color, 4, &vk_sem, vk_sem_has_wait, vk_sem_has_signal, images, ARRAY_SIZE(images), 0, 0, w, h); layout = gl_get_layout_from_vk(color_end_layout); if (vk_sem_has_signal) { glWaitSemaphoreEXT(gl_sem.vk_frame_done, 0, 0, 1, &gl_tex, &layout); glFlush(); } /* no gl rendering takes place before display */ } /*****************************************************/ enum piglit_result piglit_display(void) { enum piglit_result res = PIGLIT_PASS; int i; float colors[6][4] = { {1.0, 0.0, 0.0, 1.0}, {0.0, 1.0, 0.0, 1.0}, {0.0, 0.0, 1.0, 1.0}, {1.0, 1.0, 0.0, 1.0}, {1.0, 0.0, 1.0, 1.0}, {0.0, 1.0, 1.0, 1.0} }; GLuint layout = gl_get_layout_from_vk(color_in_layout); if (vk_sem_has_wait) { glSignalSemaphoreEXT(gl_sem.gl_frame_ready, 0, 0, 1, &gl_tex, &layout); glFlush(); } struct vk_image_att images[] = { vk_color_att, vk_depth_att }; vk_clear_color(&vk_core, 0, &vk_rnd, vk_fb_color, 4, &vk_sem, vk_sem_has_wait, vk_sem_has_signal, images, ARRAY_SIZE(images), 0, 0, w, h); layout = gl_get_layout_from_vk(color_end_layout); if (vk_sem_has_signal) { glWaitSemaphoreEXT(gl_sem.vk_frame_done, 0, 0, 1, &gl_tex, &layout); glFlush(); } /* OpenGL rendering */ glBindTexture(gl_target, gl_tex); piglit_draw_rect_tex(-1, -1, 2, 2, 0, 0, 1, 1); /* [...] */ piglit_present_results(); return res; } |
A similar test was written to validate the case where Vulkan performs a very fast rendering. In vk_semaphores2.c (vk_semaphores-2 test),
piglit_init is as we know it from previous tests and in
piglit_display. The
vk_draw is similar to that of the other image tests. I didn’t use the function
vk_clear_color from the framework, as I needed a real Vulkan queue submission. So, I prefered to clear the framebuffer by simply setting a color in the shader (although IIRC I also draw a very simple pattern).
Acknowledgments
As usually, I’d like to close this post by thanking the people who helped me complete this work:
- Tapani Palli, for his reviews, advice, and patches.
- Mario Kleiner, who found an important bug in the iris fences backend, for his bug report, proposed fix, and testing:
Next post ?!
This is going to be the last post of the series as they’ve become too long already! I started writing it on February, and I am publishing it today (August 13th) because I couldn’t find the time to complete it… 😀
I was planning to write one more final post devoted to images, to mention a few important things in image exchange, like for example the usage flags that should be used, and some details mentioned in the Issues of the EXT_external_objects spec that might be missing from my posts because I’ve realized their importance later.
Also, to explain some slightly more complex use cases, like the creation of multiple images or multiple image views from an external object.
And finally, to acknowledge more people who helped us with useful remarks and suggestions during the tests development (eg: Paulo Gomez from Samsung Research who sent us ideas and feedback several times and Nanley Chery from Intel who reviewed the final pieces of Tapani’s work on supporting combined depth-stencil formats and pointed out cases we should check like generating multiple images or views from an object!).
But I’d rather end the series here as they are already too long.
You can find more interoperability examples (eg the multiple images case) in the tests/spec/ext_external_object directory of piglit. You can also check the tests/spec/ext_external_object/vk.[hc] files if you are interested in details about the shared resource allocations (for example the selection of the appropriate usage flags).
Feel free to email me for any questions on things not covered in my posts (or you can ping me on IRC/OFTC, where my nick is hikiko).
Thanks for reading until here!! 😀 😀
Links
- [1] EXT_external_objects specification
- [2] EXT_external_objects_fd specification
- [3] GPU Ray Marching of Distance Fields
- [4] drivers/gpu/drm/i915/Kconfig.profile
- [5] Previous posts on interoperability:
- [OpenGL and Vulkan Interoperability on Linux] Part 1: Introduction
- [OpenGL and Vulkan Interoperability on Linux] Part 2: Using OpenGL to draw on Vulkan textures.
- [OpenGL and Vulkan Interoperability on Linux] Part 3: Using OpenGL to display Vulkan allocated textures.
- [OpenGL and Vulkan Interoperability on Linux] Part 4: Using OpenGL to overwrite Vulkan allocated textures.
- [OpenGL and Vulkan Interoperability on Linux] Part 5: A Vulkan pixel buffer is reused by OpenGL
- [OpenGL and Vulkan Interoperability on Linux] Part 6: About overwriting buffers
- [OpenGL and Vulkan Interoperability on Linux] Part 7: Reusing a Vulkan vertex buffer from OpenGL
- [OpenGL and Vulkan Interoperability on Linux] Part 8: Using a Vulkan vertex buffer from OpenGL and then from Vulkan
- [OpenGL and Vulkan Interoperability on Linux]: The XDC 2020 presentation
- [OpenGL and Vulkan Interoperability on Linux] Part 9: Reusing a Vulkan z buffer from OpenGL
- [OpenGL and Vulkan Interoperability on Linux] Part 10: Reusing a Vulkan stencil buffer from OpenGL
See you next time!